
In this comprehensive guide, we aim to demystify web crawlers, shedding light on their inner workings, benefits, and drawbacks. Automated web scraping, facilitated by web crawlers, has transformed the way we gather and extract data from the vast expanse of the internet. With their ability to navigate websites, collect information, and organize it for further analysis, web crawlers have become indispensable tools for researchers, marketers, and data enthusiasts alike. In this guide, we will explore the myriad benefits of web crawlers, such as accelerated data acquisition, enhanced market intelligence, and improved decision-making. However, we will also address the potential drawbacks and challenges, including ethical considerations, data quality concerns, and legal implications. By understanding both the advantages and limitations of web crawlers, you will be equipped to harness their power responsibly and make informed decisions when it comes to automated web scraping.
If you want to optimize your website for SEO (Search Engine Optimization) or you were just curious about how the search engine works, you might have heard the name web crawler bounce off in your research. If you’re thinking that it is some sort of “thing” that crawls over the internet, then you’re almost right. But let us make you absolutely right. Keep on reading to find out what web crawlers are and what are their advantages as well as disadvantages.
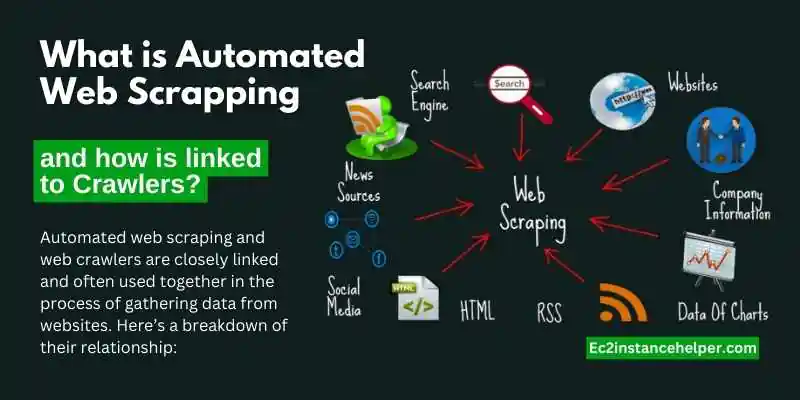
What is Automated Web Scrapping and how is linked to Crawlers?
Automated web scraping and web crawlers are closely linked and often used together in the process of gathering data from websites. Here’s a breakdown of their relationship:
Automated web scraping refers to the process of automatically extracting data from websites in a structured and systematic manner. It involves utilizing software tools or scripts to navigate through web pages, extract desired data elements, and store them for further analysis or use.
Web crawlers, also known as web spiders or bots, are a specific type of software program designed to systematically browse the internet and collect information from websites. They are the backbone of automated web scraping. Web crawlers start their journey from a given website (often referred to as the “seed URL”) and then follow links to other web pages, building a map of interconnected pages across the web.
Web crawlers utilize algorithms to traverse websites, visit URLs, parse HTML content, and extract relevant data. They typically gather information such as page titles, URLs, metadata, and other data elements that aid in indexing and understanding website structure.
In the context of automated web scraping, web crawlers are programmed to visit web pages, identify specific data elements, and extract the desired information. They navigate through the website’s structure, following links, and recursively collecting data from multiple pages.
Web crawlers can be customized to target specific data elements or follow specific rules during the crawling process. They can be designed to extract data from structured data sources like HTML tables, scrape text from paragraphs, capture images, or retrieve specific attributes from elements like URLs or product prices.
Automated web scraping often relies on web crawlers to efficiently explore and extract data from multiple web pages or entire websites. Web crawlers serve as the automated agents that navigate through websites, while the web scraping component involves defining the specific data elements to be extracted and processing the collected data.
Together, automated web scraping and web crawlers enable businesses, researchers, and data enthusiasts to gather, analyze, and utilize vast amounts of data from the web in a systematic and efficient manner. They empower data-driven decision-making, market research, competitive analysis, and various other applications that rely on web data extraction.
In short, Web crawlers are a type of software that collects, analyzes, and indexes web content. They are used to create search engines, web directories, and more. Web crawlers collect information from websites, analyze it in order to find relevant content for the target audience, and then index this content so that it can be searched later on. They also provide other tools such as social media monitoring tools and anti-spam services.
It is estimated that there are 1.18 billion websites on the internet out of which 83% are inactive. According to Google, its Google Search index data is already more than 100,000,000 gigabytes in size, and this data is of hundreds of millions of web pages – 17% of active web pages. However, it is still less than how much data the whole internet contains because the whole internet isn’t accessible by web crawlers. Specifically, the deep or dark web can’t be searched by these crawlers due to some reasons but Google is constantly trying to reach these websites and list them. Moreover, a web crawler also works according to some rules that prohibit it from visiting certain sites from indexing in the search engine.
Web Crawlers and Indexers and links to SEO
SEO (Search Engine Optimization) and web crawlers are closely linked and interdependent. Web crawlers play a crucial role in SEO by helping search engines discover, index, and rank web pages. When a web crawler visits a website, it analyzes the website’s content, structure, and other relevant factors. It collects information about the web pages, including keywords, meta tags, headings, and links. This information is then used by search engines to determine the relevance and quality of a web page for specific search queries.
- Indexing – Web crawlers are responsible for indexing web pages. They follow links from one page to another, building an index of the pages they encounter. This index helps search engines understand the content and structure of websites.
- Content Relevance – Web crawlers analyze the content of web pages, including the text, headings, images, and other elements.
- Link Analysis– Web crawlers also examine the links within web pages. They follow both internal and external links to discover new pages and assess the authority.
- Website Structure – Web crawlers analyze the structure of a website, including its navigation, sitemaps, and URL structure.
- Monitoring and Updates – Web crawlers regularly revisit websites to check for updates and changes. This allows search engines to keep their search results fresh and relevant.

Common Web Crawlers
There isn’t a specific number about how many crawlers are out there on the internet because anyone can design and deploy one. However, there are some common ones that are legal. These are:
- Googlebot for Google search engine
- Bingbot for Bing search engine
- Baiduspider for Baidu search engine
- Yahoo! Slurp for Yahoo!
- Applebot for Apple products like Siri and others
- Yandexbot for Yandex search engine
- DuckDuckBot for DuckDuckGo search engine
Moreover, a website can host an in-house crawler for its own purposes. As mentioned earlier, anyone can design and deploy their bot on the internet to perform various functions. There is no limit as to how the bots can be used, which is the reason why you see those reCaptcha’s asking if you’re a human or a robot. They just want to protect their websites from unwanted bots.
How does a web crawler work?
With so much data flowing on the internet, it is virtually impossible to read and index all of it. That is the reason why web crawlers use certain algorithms to crawl over these sites. This is how a web crawler works:
- Web crawlers start crawling from a known list of URLs or sitemaps. They copy these websites as they crawl through them.
- If they encounter other hyperlinks in a webpage, they add it to their crawling list to visit later.
- Due to the reason that this process can go on infinitely, they adopt some policies. For example, the websites which are cited more than the others are preferred as they are supposed to contain authentic information.
- Also, developers can define a robots.txt file for these web bots. This file is stored on the internet and the crawlers are supposed to follow the instructions written in them.
Robots.txt
Robots.txt, also known as the robots exclusion standard or robots exclusion protocol, is a set of instructions provided by the site developer for web crawlers. When these crawlers visit your site, they will follow the rules in the robots.txt file. Sometimes, there are such web pages where you don’t want anyone to look other than the required people; you can rule out in the robots.txt file that this particular webpage shouldn’t be crawled. Also, there are some malicious crawlers out there that can slow down your website; you can’t ban these crawlers using the robots.txt file.
Sitemaps
Sitemaps are XML files that contain all the URLs related to a particular web domain. The developer might add additional information like when this particular web page was last edited and update its metadata. Sitemaps can be very useful to list contents that are very different from the other content available on your website.
If both robots.txt and sitemap are used in conjunction, they will yield an optimized SEO performance which will help your site to list better in the browser Search Engines.
Pros of web crawlers
1. Easy to gather data
Sometimes you just want to collect all the information of a website. Manually going through each site and then copying the information is a tedious task. However, if a web crawler is used for this purpose, the task becomes easier. Crawlers can easily and efficiently extract data from a webpage and store it for future use.
2. Increased site-traffic
Web Crawlers are responsible for finding authentic sources of information on the internet and then listing them accordingly. If you wish your site to be indexed higher on the servers, you need to provide a proper sitemap and robots.txt file, and also you have to display quality content. If your site gets listed, then it will result in increased traffic which means increased income.
3. Keep track of user activity
We all want to provide our users and viewers with the most interactive and high-quality content. To achieve that, it is important that we first record and analyze how users are spending time on our websites. This way, it will be easier for us to find bad spots and correct them hence increasing user comfort. If a user feels good after visiting your site, it is already a win-win condition for you.
Before you track a user’s activity, you should notify them about it and ask for their permission because some people don’t like to be monitored. It is your duty as a web admin to keep in mind your user’s privacy and work according to it.
4. Keep track of important information
Here, important information is an umbrella term for any data that a certain company might find useful. For example, keeping up with industrial trends and noticing the moves of rival companies are important tasks in the business field. To achieve that, web crawlers can be designed to keep track of this information and store it for future use.
Moreover, a developer can program these crawlers to analyze this data and prepare meaningful charts and graphs that convey the required information.

Cons of a web crawler
1. Malicious Bots
With great advantages, comes a great disadvantage. And this is probably the biggest disadvantage there is of web crawlers. Just like there are good crawler bots, there are bad crawlers too. These bad crawlers want to scrape your site data and use it for malicious purposes. These evil purposes can cause a lot of damage to your website and you don’t want that.
2. Data Breach
Evil crawlers might scrape your sensitive data stored over the internet and then make it publicly available or sell it. This will lead to a data breach in your system and not only that, the user’s trust in you will also degrade.
3. Too much traffic
Whether it is due to your listing in the Search Engines or malicious bots trying to overload your server, if your site gets too much traffic and it isn’t designed for that, bad things might happen. For example, an increase in traffic might result in decreased bandwidth which will ruin the user experience further degrading your site. The repair process is lengthy and costly which will create a financial imbalance in your life.
4. Prohibited pages
A web crawler isn’t supposed to list private web pages such as login pages, data reports for your company, and other kinds of secrets. This can be easily prevented by using the robots.txt file and sitemap. But malicious bots don’t follow these sitemaps and they might try to copy this secret information. To prevent that, you should consider using a firewall on your private files stored over the internet.
Conclusion
The conclusion is that if good web crawlers crawl on your site that it is a win-win situation. But if the bad ones try to copy your content and information then you should be aware of that and plan to counter that issue.
Web crawlers are an essential part of Search Engine Optimization as they are responsible for listing the websites on the servers. If you are able to clearly communicate with these crawler bots and you pass all their policies, then there is a high chance that you might get listed higher in the chain. This will result in more visitors to your website which is something we all want.